

I’m not a Foucauldian, but it’s pretty useful sometimes to put on that bald Foucault hat to think in terms of governmentality. Especially now that Tumblr has announced that it is going to purge adult content from the website on December 17, 2018, and has already started using bots to flag
This is not a post about why the announcement that Tumblr would be purged of adult content on December 17, 2018 is dumb and harmful. We all know that it is stupid. We all know a Puritanical purge does nothing to protect child trafficking victims and it is using the cultural fixation on “the innocence of the child” (not too get too Lee Edelman here) as its rationale, presumably under the assumption that this rational is so culturally sacred that no one would dare reject it despite, again, it not helping children in any way. I have an ongoing Greatest Hit list at the end for writing on this subject.
No, this is about algorithmic sorting as a moralizing framework. In “Animalizing Technology in a Posthuman Spirit,” Damien Smith Pfister writes that algorithms are not only “interpretative frameworks” but interpreters. They make meaning out of the social reality they are created to compute based on the values encoded into them. They also act as performative infrastructure for the world around us in ways like shaping our interfaces, in traffic and city planning, indexing what search results Google presents for each individual in accordance to things like online and offline activity (including what websites you visit at what time and on what server), etc. Thus this contributes to how certain values are “encoded” into our world
If there’s one good thing to come out of Tumblr putting its foot in its mouth and shooting itself in it, it’s that I now have a really concrete example for what can be a somewhat vague phenomenon.

(example of a flagged post).
Let’s begin by dispelling the idea that the flagging algorithms shall improve.
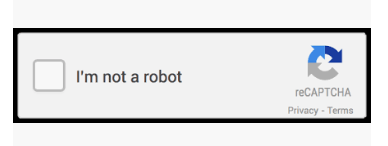
First off, recognizing images is one of the hardest things for algorithms to do. This is why image recognition is a common feature for CAPTCHA. Let me put it this way: Imagine screenshotting an Tweet or a Tumblr post, then repost it to Twitter or Tumblr. That screenshot is an image. It will be read as an image. It will not be read as text. This is why you will see a screenshot of a Tweet on Tumblr followed by the text of the tweet repeated verbatim in the description. This is to make it accessible to screenreader software, that can only read text. Similarly, the phrase “I am not a robot” below is an image, NOT text coded into the webpage. Bots have a harder time identifying images. Whereas if “I am not a robot” was coded as text, it would be easy to program a bot that could read and click “I am not a robot.”
Oh sure there is Visual Chatbot and the machine learning algorithm that draws things discussed in, ironically, a Tumblr post I suspect may be gone in a week.

(pictures of humans drawn by machine learning algorithm GANattn).
As the imperfections in these (quite impressive) projects suggest, we are a long way off algorithms identifying nudity or pornographic material with any accuracy.
Whoever’s decision it was to implement this plan knows full-well how how difficult identifying images is for software agents. Thus, they truly do not care. Apathy, like all else in business, has an economic rationale. It is possible that Tumblr is simply not lucrative enough to Verizon. It may be the case that it makes more money with them to get it on the Apple Store and in with advertisers as quickly as possible, and then sell the site at a lower rate when/if the user activity drops for more money than they would make running Tumblr with reduced ads. This brings me to my second point: if Tumblr has not responded to user criticism yet by scrapping the plan, they won’t.
I’m not a Foucauldian, but it’s pretty useful sometimes to put on that bald Foucault hat to think in terms of governmentality. Especially now that Tumblr has announced that it is going to purge adult content from the website on December 17, 2018, and has already started using bots to flag accounts. Algorithms delegate decisions related to public education, traffic and urban planning, plagiarism identification, loan applications (x) sentencing and parole eligibility (x), purchase history surveillance in order to determine eligibility for welfare assistance and identify “at risk” children for child abuse, categorize areas at “at risk” for disease or fire as well as individuals “at risk” for committing crime or developing obesity, evaluate and organize online communities through filtering and suggestions on social media, search engines, and other realms of online interaction, direct military drones to target locations, curate online content through search engine personalization, and use this content curation to influence “off-line” activity as well, including likeliness to vote. These practices have consequences for how values and decision-making are coded into transmediation of bodies, space, or time into data. The way that we co-conduct networked activity in public policy, medicine, war, welfare, and “the news” refigure what is a “public issue” (what is a “public?” what is an “issue?”). What is “health?” How do we code a “body.” What kinds of people are an acceptable “risk” for releasing a non-re offender in to the community, or being a “worthy” for a welfare recipient (what is “safety” (to whom?), what is a community (and who counts?), who is a “risk” (to what?), what is “worth?”). What is a “target,” or, what is the acceptable margin of error in target selection by drone (who is an acceptable collateral damage)?
Algorithms are created to “solve a problem” by computing “in-puts” into “out-puts.” But who decides what a problem is? What role does algorithmic activity — by which I mean the various processes we colloquially call “algorithmic” (since algorithms are not “things” but that is another topic) — play within intricate networks of action in which human and nonhuman activity performatively (Endnote) construct? It is fairly obvious that with language like “female presenting nipples,” that the programming represents and re-produces cultural values. Let’s not even get into the “art vs porn” conversation that gives me flashbacks to the 1921 court case and obscenity laws around Ulysses. What maybe less obvious is that this contributes to normalizing not only what is censored and how, but what is produced.
There’s a lot to critique about the model of the “the filter bubble” — another essay — but personalization is not negligible in terms [x] of the role that directing traffic to different online content have in the creation of publics. This isn’t necessarily direct censorship, but a manipulation of data exposure that can still operate to silence voices in practice. Now, these practices operate often without direct intention on the part of a company, a “independent” platform or an individual. YouTube’s recommendation algorithm programmers are probably not white supremacist conspiracy theorists but here we are.
I should also add blaming individual software programmers or teams is not productive, by the way, since this thing can be really hit and miss. But there is a responsibility for anyone overseeing implementation to check this shit (Which is why I think I’ve recommended boyd’s short blog post on strategic amplification a dozen times this year). With the Puritan Bots of Tumblr, the editorial decisions are being made by algorithms. This also leads to standards of content production. Predictive modeling by algorithms as seen in the use lead to content creation. We see this in how Netflix and the film industry use programs like Equinox to decide which original series and films to produce. We also see it in algorithmic news distribution that predicts what news is most relevant to local news stations (as seen in AOL’s Patch). What projects are pitched and what scoops are collected can evolve in response (the journalism example is much more complicated and it should be noted automatization in journalism is not necessarily a bad thing. Save that one for later). In other words, algorithms that predict trends can cause trends. Similarly, what is monitored on Tumblr and elsewhere on the internet does lead to what people create in order to gain visibility and make money. This, in turn, can participate in what a wider culture lets themselves “think.”

The ease of practicing flat censorship algorithmically instead of using human content monitors (WIRED) gives credence to McQuillan’s theory of an “algorithmic age of exceptionalism,” in which business models exercise censorship power and, apparently encouragement of the arts (my conjecture, not McQuillan’s) in a parallel realm that may be adjacent to state interests, but not even necessarily demanded by the state.
And that fucking sucks.
Reading Recs
Annay “The Curious Connection Between Apps for Gay Men and Sex Offenders.” (2011) (note: This is an Atlantic op-ed but Annay is an academic whose work on public ethics of communication systems is worth checking out if this new to anyone reading this. I’d actually suggest tracking down some of his op-eds in the news or videos lectures on places like Data & Society. He’s not my favorite EVER but he’s good and his general arguments usually hold up from what I’ve seen).
boyd and Caplan “Who Controls the Public Sphere in the Age of Algorithms?”
(anything boyd has ever written for Data & Society is gold. I have not actually read any of her books full disclosure).
McKelvey “Algorithmic Media Needs Democratic Methods” and the blog post “No More Magic Algorithms: Cultural Policy in an Era of Discoverability.”
McKenzie Programming Subjects in the Regime of Anticipation
McQuillan “Algorithmic States of Exceptionalism” (you don’t have to have read Agamben, he gives a nice concise, accessible summary).
Pfister Animalizing Technology in a Posthuman Spirit (this one is particularly philosophy and theory heavy but the part about algorithms as not only moral frameworks but moralizing interpreters is in early).
Wikipedia on the Obscenity Trials of James Joyce. Seriously even if you care nothing of Joyce this is a really important historical precedent for talking about the legislation of “porn vs art.”
The Moral Dilemma of Algorithmic Censorship
On Tumblr in particular:
This Motherboard post has been going around (Apple Sucked Tumblr Into Its Walled Garden) but searching the site for the keyword Tumblr provides almost a chronology of headlines to How We Got Here.
“Why Social Media Platforms Should Think Twice Before Banning Adult Content” (July 2017). Short and eerily precedent. Written over a year and a half ago!
“Dear Tumblr: Banning “Adult Content” Won’t Make Your Site Better.”
Endnote:
- By “performative,” I mean in the Judith Butler and Karen Barad sense of “self”-constituting in time by repetitive re-itetation. Not “putting on a performance.”

3 comments